 Although the thought was revolutionary back in 2002, librarians now widely recognize that our metadata requirements have outgrown the MARC standard. After 50 years of service it’s time to make library data more actionable and linkable on the web. But to do that we need to bring our existing data assets into some sort of new regime. And doing that well is going to take understanding what we have to work with.
Although the thought was revolutionary back in 2002, librarians now widely recognize that our metadata requirements have outgrown the MARC standard. After 50 years of service it’s time to make library data more actionable and linkable on the web. But to do that we need to bring our existing data assets into some sort of new regime. And doing that well is going to take understanding what we have to work with.
Before I go on I need to make it clear that when I say “MARC” I’m really conflating a number of things that attempt to describe and control which data elements are recorded and how. For the purposes of this piece, MARC comprises the various flavors of the MARC standard (primarily MARC21), cataloging rules as expressed in AACR (first edition 1, then edition 2), and even punctuation rules as described by ISBD. These are the foundational elements of the library bibliographic universe as it has been developing since the 1960s.
In a perfect world these standards would have described exactly the right things to do and the right ways to accomplish them and they would have been widely understood and uniformly applied. This is not a perfect world.
So as the profession moves forward to create a new bibliographic infrastructure that is web-ready, linked and linkable, an important — indeed vital — question that must be answered is: What do we have to work with? That is, if we want to create canonical linked data entities for elements like authors, subjects, works, etc. we need data that is largely machine actionable in some critical ways. In other words, instead of looking at our data from afar, as satellites look at the Earth, we must “ground truth” our data just as those working with remote sensing do — we need to check our perceptions on the ground to make sure they are accurate. This is what my project, “MARC Usage in WorldCat” has been doing for the last 3 years.
For example, look at how many ways we have recorded the fact that an item includes “illustrations”. It’s clear that processing any of our data will require a lot of normalization, at minimum, to be able to understand that “ill.” and “illustrations” and “ilustrations” and “ilustr.” and “il.” and whatever, all mean the same thing.
This is not the only use for the site, as Reinhold Huevelmann at the German National Library (DNB) points out:
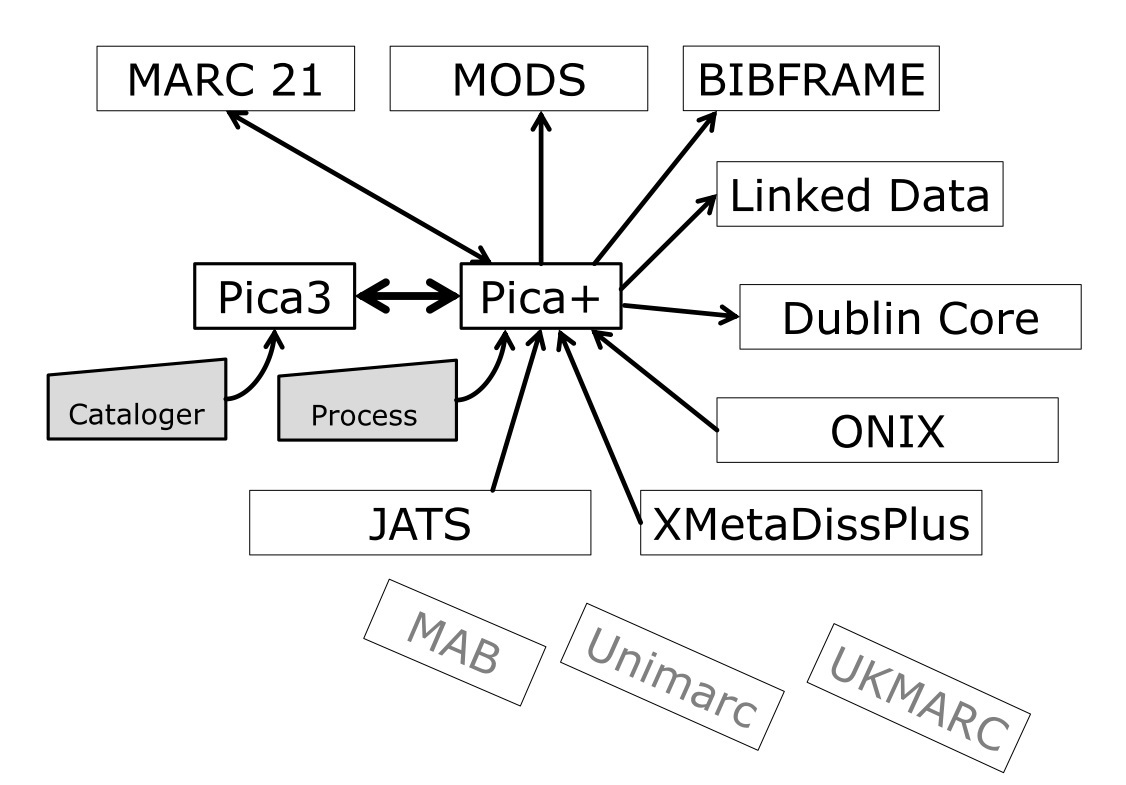
Mapping an element from an internal metadata format, e.g. Pica+, to MARC 21 (see http://www.heuvelmann.de/Pica_Turntable.jpg ) sometimes needs grounded discussions and informed decisions. In cases of doubt, apart from the MARC 21 standard and its documentation, the reality of MARC 21 data elements used in OCLC’s WorldCat provides good guidance in choosing the right target element, to prevent theoretically available, but exotic options, and thus to enhance the visibility of bibliographic data and the resources described.
{kind=link}
As Reinhold points out, the standards are one thing, but another is how they have been used “on the ground”. There are often decisions that must be made between competing options and it can be helpful to know what decisions others have made.
Thus this project is unlike most of what OCLC Research does, as it does not come to any conclusions, but rather is a tool that can be used to help you reach your own conclusions about library bibliographic data and how it continues to evolve over time. A side benefit has also been that occasionally we catch errors that can be corrected.
Roy Tennant works on projects related to improving the technological infrastructure of libraries, museums, and archives.
>> As Reinhold points out, the standards are one thing, but another is how they have been used “on the ground”.
I wonder how many people haven’t realized that applies to linked open data as well.
Exactly. And the implications of bad or inconsistent data becomes even more damaging in a linked data environment.