The following post is part of an ongoing series about the OCLC-LIBER “Building for the future” program. A Dutch version of this blog post is also available.

The OCLC Research Library Partnership (RLP) and LIBER (Association of European Research Libraries) hosted a facilitated discussion on the topic of AI and machine learning on 17 April 2024. This event was a component of the ongoing Building for the future series exploring how libraries are working to provide state-of-the-art services, as described in LIBER’s 2023-2027 strategy.
As with the previous sessions in the series, on the topics of research data management and data-driven decision making, members of the OCLC RLP team collaborated with LIBER working group members to develop the discussion questions and support small group discussion facilitation.
The virtual event was attended by participants from 31 institutions across twelve countries in Europe and North America, and this post synthesizes key points from the small group discussions.
Curiosity, confusion, and uncertainty
We kicked off the event by asking participants how they feel about the use of AI and machine learning in libraries, and they responded with a range of complex emotions. While curious and interested about the uses and future of AI, librarians are also skeptical and apprehensive.

In the small group discussions, participants expressed significant concerns about:
- Environmental impacts due to significant energy usage
- Privacy of user data
- Use of copyrighted materials in LLMs and uncertainty about intellectual property ownership
- Misinformation created by the inaccuracies and hallucinations delivered by generative AI
- Risks of nefarious manipulations, particularly of voice recordings
- English language dominance in LLM models
- The ability to acquire relevant and usable information amidst intense information overload
Upskilling is lonely work. Most people are acting independently to develop their own AI knowledge, through experimentation with an array of tools, and virtually everyone participating in these discussions reported being in the experimentation and learning phase. More structure and support is sorely needed, and a few participants described how they had benefited from a team approach, such as through the establishment of an AI interest group in their library, or by participating in facilitated discussions such as this one.
What’s in their AI tool kit? We asked participants about the tools they are using, and ChatGPT unsurprisingly dominated the list, followed by Microsoft Copilot. Mention of tools like Transkribus, eScriptorium, and DeepL reflect library interests in text and image transcription, analysis, and translation, while a long tail of products like Elicit, Gemini, ResearchRabbit, Perplexity, and Dimensions AI reflect an interest in research discovery and analysis.
Discussions about AI in libraries are strongly influenced by their institutional contexts. Many participants described a pervasive institutional focus on concerns about academic integrity. Policies and guidelines are emerging at local, consortial, and association levels, such as the principles on the use of generative AI tools in education from the Russell Group of research universities in the United Kingdom, which emphasizes not only academic integrity but also the role of universities in supporting AI literacy and equitable access among its affiliates.
Research universities are beginning to provide enterprise services. A few US institutions are launching local chatbots for use by faculty, staff, and students. Participants from the University of California-Irvine shared about the institutionally-supported ZotGPT, built upon the Microsoft Azure platform, which is provided to campus users at no cost. By providing a local tool, the institution can equalize access to experimentation while also overcoming privacy concerns, as the data inputs remain local. This is almost certainly an area we will see more growth in.
AI use cases in libraries
We asked participants to consider the ways libraries can leverage AI, resulting in a rich mine of potentialities, which I have organized into six high-level use case categories:
- Metadata management
- Reference support
- Discovery and content evaluation
- Transcription and translation
- Data analytics and user intelligence
- Communications and outreach
Metadata management topped the list. We heard several participants mention an interest in using machine learning models to create MARC records, and indeed, we heard numerous examples of exploration in this area. For example, the National Library of Finland has experimented with automated subject indexing, resulting in the Annif microservice. In the United States, LC Labs at the Library of Congress has undertaken a project called Exploring Computational Description (ECD) in order to test the effectiveness of machine learning models in the creation of MARC record fields from ebooks. You can learn more via this recorded OCLC RLP webinar. Other participants described local efforts to use textual information to generate subject headings as well as experiments to use tools like Gemini. Participants found their early results disappointing, as they mostly offered a lot of “fictional data,” but still remained optimistic about the potentialities.
In addition to metadata creation, participants are interested in how AI and machine learning technologies may be used to improve metadata quality. This could include anomaly and duplicate record detection or perhaps detection of incorrect coding of languages in records. OCLC has shared about its use of machine learning to identify duplicate records in WorldCat, with input from the cataloging community.
Reference support. Several participants expressed an interest in leveraging AI in order to create a library reference chatbot, in order to instantly answer questions that can be answered by information on local web pages. A participant from the University of Calgary briefly shared how their library has implemented a multilingual reference chatbot called T-Rex, which leverages both an LLM as well as retrieval-augmented generation (RAG), and is trained on the library’s own web content, including LibGuides, operating hours, and much more. In operation for over a year, the effort has been successful and appreciated by librarians, as it reduced the amount of human support required for simple questions.[1]
Discovery and content evaluation. Participants are also interested in how AI technologies can enhance discovery, for example, by enabling searching with natural language phrases in addition to keywords. We heard about some innovative projects at national libraries to support discovery use cases, such as a chatbot answering questions from the digitized newspaper collection at the National Library of Luxembourg.
Researchers are using a number of freestanding tools like scite, Consensus, ResearchRabbit, Perplexity, and Semantic Scholar in order to summarize relevant findings from aggregated content, receive citation recommendations, and visualize research landscapes. The Generative AI Product Tracker compiled by Ithaka S+R offers a useful guide to this ecosystem. In addition, participants described researcher uptake of new AI functionality being built into existing research indexes like Scopus and Dimensions. Like the reference chatbot example above, it appears that these tools use a combination of retrieval-augmented generation (RAG) to query only the local index and generative AI, which processes the returned information into an answer to the original question while minimizing hallucinations.
Transcription and translation. Librarians are keenly interested in transcribing tools, which can increase the accessibility and use of cultural heritage collections. In the discussions, we heard about speech-to-text experimentation (using automatic speech recognition (ASR) technology) taking place at the National Library of Norway and the Royal Danish Library. Several participants mentioned using the Transkribus and eScriptorium platforms to support text recognition and image analysis of digitized historical documents. There’s also interest in how these tools can support researchers working in languages where they have poor proficiency.
Data analytics and user intelligence. While not at the top of the list, more than one participant expressed an interest in using data science and AI tools to learn more about patron behaviors in order to support improved library management.
Communications and outreach. One participant described how their library is using ChatGPT to generate content for library social media feeds, with human review. This seems like a general purpose use case that I expect to hear more about.
Supporting responsible operations
Participants discussed the need for responsible AI practices, particularly the need for AI to be transparent, accountable, and inclusive. There was considerable focus on the need for transparency of LLM data sources, including an examination of the legality of data scraped for use in training sets. In addition to previous reports like OCLC Research’s Responsible Operations: Data Science, Machine Learning, and AI in Libraries, many other research projects, statements, workshops, and events are emerging to guide libraries in ethical decision making about AI. Just a few of these include:
- Responsible AI in Libraries and Archives (IMLS-funded project at Montana State University)
- LC Labs AI Planning Framework
- The upcoming LIBER Annual Conference, 3-5 July 2024, where AI is a central theme that will be interrogated through keynotes, workshops, and presentations
- Research Libraries Guiding Principles for Artificial Intelligence (Association of Research Libraries)
Participants shared their thoughts on how libraries can lead, which included chairing campus discussions about AI literacy, uses, and good academic practices. The LIBER Data Science in Libraries Working Group (DSLib) has been discussing how libraries can interact with AI-generated misinformation and fake news.
Leadership roles for libraries in AI literacy
A principal way that libraries can and are leading is in supporting AI literacy education and training, which many participants described as the newest component of information literacy training. To guide students and researchers, librarians must quickly upskill in order to teach others.
What do libraries require for success?
Through these conversations, I heard participants describe many things that libraries need to successfully move forward. At the most basic level, librarians need access to tools and the time to practice and experiment. Only through these preconditions will librarians gain the content mastery necessary to both serve as campus experts to users and to lead library-based efforts. For example, one participant described how librarians must be familiar with LLM hallucinations, including the creation of fake citations, in order to have the knowledge and confidence to work with patrons using chatbots. Another local need is for more professionals with data analytics skills to be situated in the library, working as part of a cross-functional team, consistent with comments we heard in a previous session about data-driven decision making.
Skills development is independent and ad hoc at this point. Participants want more training guides, external support and sample use cases, and they also want to engage meaningfully with others in communities of practice.
Looking ahead
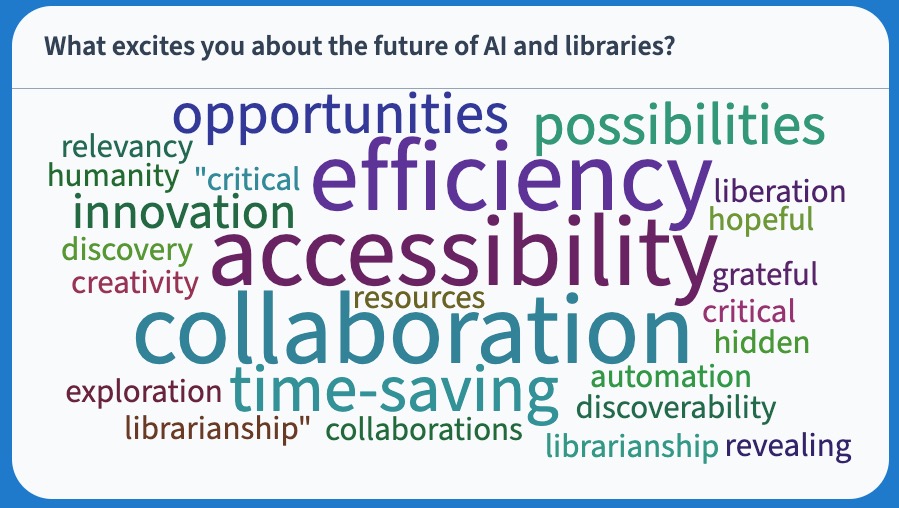
These small group discussions are valuable for connecting library professionals across many time zones. Some participants reported feeling reassured that others were grappling with the same uncertainties at early stages of discovery and experimentation. Overall, participants reported feeling excited and hopeful about the opportunities for AI to support greater efficiency and time-savings in libraries.
Join us on Thursday, 6 June for the closing plenary event of the OCLC-LIBER Building for the Future series. This session will synthesize the high level takeaways from the previous small group discussions, followed by a panel discussion by library thought leaders, who will respond with their perspectives on how research libraries can collaboratively plan in these challenging times. Registration is free and open to all. I’ll see you then.
[1] Julia Guy et al., “Reference Chatbots in Canadian Academic Libraries,” Information Technology and Libraries 42, no. 4 (December 18, 2023), https://doi.org/10.5860/ital.v42i4.16511.
Rebecca Bryant, PhD, previously worked as a university administrator and as community director at ORCID. Today she applies that experience in her role as Senior Program Officer with the OCLC Research Library Partnership, conducting research and developing programming to support 21st century libraries and their parent institutions.