In November, we shared information with you about the Building a National Finding Aid Network project (NAFAN). This is a two-year research and demonstration project to build the foundation for a (US) national archival finding aid network. OCLC is engaged as a partner in the project, leading qualitative and quantitative research efforts. This post will gives some details on just one of those research strands, evaluation of finding aid data quality.
In considering building a nationwide aggregation of finding aids, looking at the potential raw materials that will make up that resource helps us to both scope the network’s functionality to the finding aid data and to lay the groundwork for data remediation and expanded network features.
We have two main research questions when approaching the finding aid data quality:
- What is the structure and extent of consistency across finding aid data in current aggregations?
- Can that data support the needs to be identified in the user research phase of the study? If so, how? If not, what are the gaps?
About the research aggregation
Twelve NAFAN partners made their finding aids available to the project for quantitative analysis, producing a total of over 145 thousand documents. The finding aids were provided in the Encoded Archival Description (EAD) format. EAD is an XML-based standard for describing collections of archival materials.
As a warning to the reader: this post delves deeply into EAD elements and attributes and assumes at least a passing knowledge of the encoding standard. For those wishing to learn more about the definitions and structure, we recommend the official EAD website or the less official but highly readable and helpful EADiva site.”

This treemap visualizes the relative proportion of the finding aid aggregation from the partners:
- Archival Resources in Wisconsin
- Archives West
- Arizona Archives Online (AAO)
- Black Metropolis Research Consortium (BMRC)
- Chicago Collections Consortium
- Connecticut’s Archives Online (CAO)
- Empire Archival Discovery Cooperative (EmpireADC)
- Online Archives of California (OAC)
- Philadelphia Area Archival Research Portal (PAARP)
- Rhode Island Archives and Manuscripts Online (RIAMCO)
- Texas Archival Resources Online (TARO)
- Virginia Heritage
Though a few of the partners provided much of the content, the aggregation is a very good mix from a wide variety of United States locales and institution types.
Dimensions for analysis
This analysis continues work carried out previously, including a 2013 EAD tag analysis that OCLC worked on with a different aggregation of EAD documents, based on about 120,000 finding aids drawn from OCLC’s ArchiveGrid discovery system. You can check out that previous study, “Thresholds for Discovery: EAD Tag Analysis in ArchiveGrid, and Implications for Discovery Systems” published in code4lib Journal issue 22.
OCLC’s 2013 analysis looked at EAD tag and attribute usage from a discovery perspective. For that study, we identified five high-level features that were often present in archival discovery systems.
- Search: all discovery systems have a keyword search function; many also include the ability to search by a particular field or element.
- Browse: many discovery systems include the ability to browse finding aids by title, subject, dates, or other facets.
- Results display: once a user has done a search, the results display will return portions of the finding aid to help with further evaluation.
- Sort: once a user has done a search, they may have the option to reorder the results.
- Facet: once a user has done a search, they may have the option to narrow the results to only include results that fall within certain facets.
The analysis used that framework of high-level discovery features to select EAD elements and attributes that, if present, could be accessed, indexed, and displayed.
This is the categorization of EAD elements and attributes that the study found to be relevant for supporting discovery system features.
- Dates: unitdate
- Extent data: extent
- Collection title sources: unittitle, titleproper/@type=filing
- Content tags in dsc: corpname, famname, function, genreform, geogname, name, occupation, persname, subject
- Content tags in origination: corpname, famname, name, persname
- Content tags in controlaccess: corpname, famname, function, geogname, name, occupation, persname, subject
- Material type: controlaccess/genreform
- Repository: repository
- Notes: abstract, bioghist, scopecontent
For example, dates could potentially be utilized as search terms, or leveraged for for browsing or sorting. They may also be important for disambiguating similarly named collections in displays. Similarly, material types, represented by form and genre terms, could be important for narrowing a large result using a facet.
(Thank you to eadiva for providing the excellent tag library that is linked to from the EAD elements names above.)
The question then was, how often are these key elements and attributes used?
Defining Thresholds for Discovery

We should preface this by saying that it is difficult to predefine thresholds for the level of usage of an element at which it becomes more or less useful for discovery. Is an element that is used 95% of the time still useful but one that is used 94% not?
OCLC’s 2013 study developed these thresholds after evaluating the EAD aggregation. The absence of an element does not directly lead to a breakdown in a discovery system. It is more like a gradual decay of its effectiveness.
Although we used these levels as a reference point in the 2013 study, we recognized that correlating usage with discovery is an artificial construct.
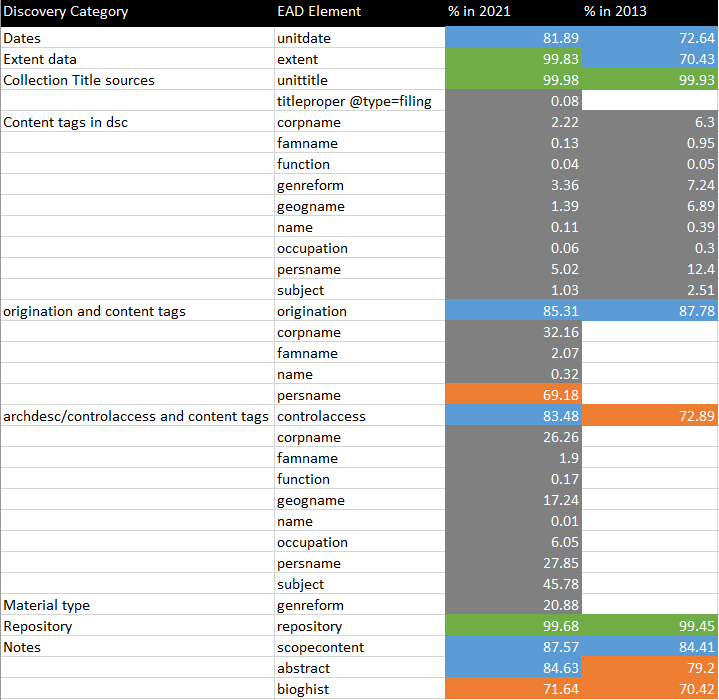
The above figure shows a comparison of the usage thresholds from the 2013 study (right), compared with the same tag analysis applied to the NAFAN corpus in 2021 (left).
You will notice that there are some elements that we have added for analysis in the 2021 study, thanks to input from the expanded project team and the advisory board which is reviewing / providing input into work. This input has helped to breathe new life into old research.
The findings of the 2013 study were decidedly mixed. Some important elements were at the high or complete thresholds. But many elements that are necessary for discovery interfaces were at medium or low use. Though the NAFAN EAD aggregation is a different corpus of data provided by different contributing institutions at a different time, the EAD tag analysis for it hasn’t changed the picture very much.
A few elements have moved from the high threshold to complete, and a few from medium to high. And we found that there was mostly low-level use of content tags in origination and control access. Apart from that, the 2013 study’s appraisal of how well EAD supports the typical features of discovery systems could be considered mostly unchanged. This may be due in part to the relatively static nature of EAD finding aids. Once written and published, some documents may not receive further updates and improvements. It is not uncommon to find EAD documents in this aggregation that were published several years ago and have not been updated since.
Looking back on the conclusions of the 2013 study suggests that its cautionary forecast about underutilization of EAD to support discovery has proven to be accurate, while the study’s vision of the promise and potential for improving EAD encoding has yet to be fulfilled.
If the archival community continues on its current path, then the potential of the EAD format to support researchers or the public in discovery of material will remain underutilized. Minimally, collection descriptions that are below the thresholds for discovery will hinder their discovery efforts and maximally will remain hidden from view.
Perhaps with emerging evidence about the corpus of EAD, continued discussion of practice, recognition of a need for greater functionality, and shared tools both to create new EAD documents and improve existing encoding, we can look forward to further increasing the effectiveness and efficiency of EAD encoding and develop a practice of EAD encoding that pushes collection descriptions across the threshold of discovery.
Thresholds for Discovery: EAD Tag Analysis in ArchiveGrid, and Implications for Discovery Systems
More research opportunities
Though replicating the 2013 EAD Tag Analysis was an important step to confirm what we previously understood about the content and character of EAD finding aids, it only scratched the surface of what’s left to learn. While OCLC’s qualitative research is still being carried out and its findings won’t be available until later in the project, we can pursue other quantitative research right now to learn more about the NAFAN finding aid aggregation.
Here are some of the areas that we’re investigating:
- What is the linking potential of the NAFAN EAD finding aids?
- What is the completeness and consistency of the description of collections’ physical characteristics and genre?
- Are content element values associated with controlled vocabularies, or can they be?
- Is institutional contact information in EAD finding aids consistent and reliable?
- How do EAD finding aids inform researchers about access to, use of, and reuse of materials in the described collections?
There are many possible avenues for research, but we want to be truly informed by the focus groups and researcher interviews before investing additional effort.
The first area of investigation noted here about finding aid links to digital content correlates with early findings from OCLC’s NAFAN pop-up survey which show that, for many users, only digitized materials would be of interest.
Investigating the linking potential of the aggregated finding aids could help answer several questions, including:
- What is the average number of external links per finding aid?
- What EAD elements and attributes are most frequently used for external links?
- What types of digital objects are linked?
- How many relative URLs are present, that rely on the finding aid to be accessed within its local context?
- What percentage of external links still resolve?
OCLC will be investigating these areas and publishing findings over the coming months. Please get in touch with us if you’d like to discuss this work in more detail.
Bruce Washburn (retired, 2021) was a Principal Software Engineer in OCLC Research. He provided software development support for OCLC Research initiatives and participated as a contributing team member on selected research projects. He operated the ArchiveGrid discovery system and provided software development support for selected OCLC Products and Services.
@Bruce, thank you! I’m looking forward to seeing what comes next.
@Kate, Bruce’s response is consistent with the information I have and with the findings in the NAFAN report, https://escholarship.org/uc/item/5sp13112.
Thank you to Kate and Jodi for kicking off the conversation, and to Bruce for providing answers!
One difference between 2013 and 2021 is the EAD encoding environment and workflows that finding aid creators inhabit. In 2013, many archivists were creating EAD either directly or through bulk means and then proofing and validating their work in native EAD. In 2021, many more are using metadata management systems such as ArchivesSpace that output EAD. In the mean time, lots of that 2013 and earlier data was migrated into such systems. And, of course, a lot of the 2013 data might have been retrospective encoding of previously analog or unparsed data sources, like word-processed or html finding aids. Do you have information on the origination of the EAD tagging in the study or the date of the creation of the finding aids studied?
I know this is a lot to ask!
Thanks!
Hi Kate, Sorry for the delay in responding. We have some partial information on the origination of the tagging and the most recent update date for the data. That information indicates that, for a significant portion of the corpus, the finding aid data was produced a decade or more ago, without indications that it has been updated since. And some of it originated as part of conversion programs for physical finding aids, as you noted. I’ll see if our data would support a deeper analysis to help us better understand its origins and vintage.
Bruce and all, this is fascinating , both as a comparison and a snapshot of the current state! I’m really glad to see this work as part of the NAFAN project.
One tag that I’m curious about but don’t see here is the tag and attributes url= and the use of ARKs or other durable identifiers. I imagine that will be part of your forthcoming analysis and look forward to seeing more!
Hi Jodi, I apologize for the long delay in responding. We have another data analysis project that focuses on the linking potential of finding aids. I’ve extracted the relevant tags and attributes and have done some initial sorting, but do not have results quite ready to publish here, it will probably be another month or so.