Are EAD content headings associated with controlled vocabularies, or can they be?
For names of people, families, organizations, subjects, places, and genre forms, the EAD Tag Analysis conducted by OCLC Research in 2021 as part of our contribution to the Building a National Finding Aid Network (NAFAN) project describes how frequently these content tags are used, but a closer look at their element and attribute values can reveal how much work has been done to associate those values with identifiers for the entity in a controlled vocabulary, and also can provide a testbed for evaluating the potential for using automated tools to attempt further reconciliation.
As a warning to the reader: this post delves deeply into EAD elements and attributes and assumes some familiarity with the encoding standard. For those wishing to learn more about the definitions and structure, we recommend the Library of Congress EAD website and the highly readable and helpful EADiva website.
Inclusion of authority file numbers is infrequent, but identification of controlled vocabulary sources is more common
The EAD elements describing people, families, organizations, subjects, places, and genre form terms were extracted from the corpus of over 145 thousand finding aids provided by NAFAN participants. All of these EAD documents used the EAD2002 DTD or Schema; no EAD3 documents were provided for the NAFAN data analyses.
The tabulation of elements that included values for the authfilenumber (a number that identifies the authority file record for an access term) and source (indicating the controlled vocabulary source of the heading) attributes indicates that fewer than 10% of these elements provided an authfilenumber, but 40% or more of the elements included a source value. For example, in the extraction of 1,092,209 persname elements, 94,365 (8.6%) included an authfilenumber attribute value while 595,048 (54.5%) included a source attribute value. Establishing the source can improve the efficiency and accuracy of reconciling headings with a controlled vocabulary.
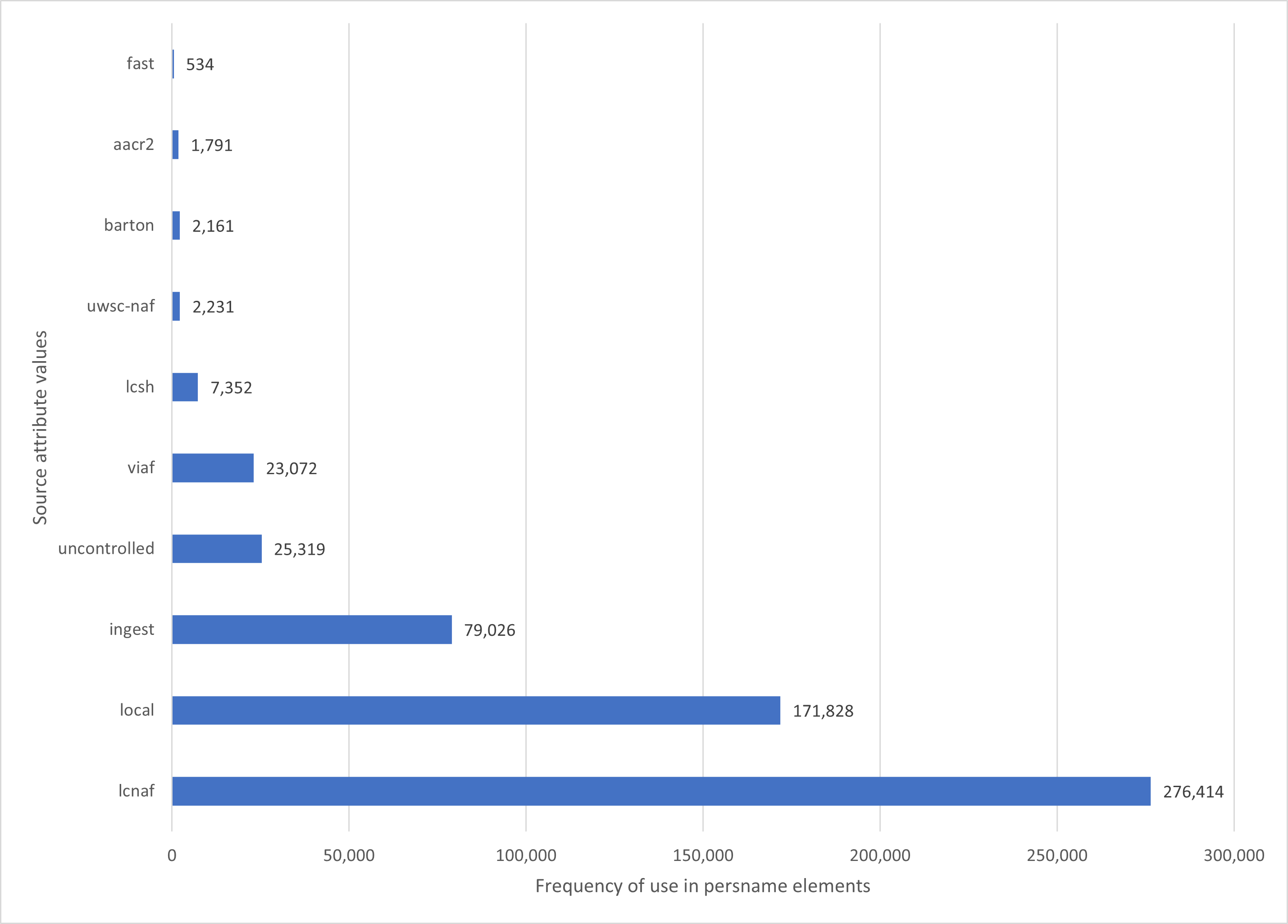
Not surprisingly, a small number of widely used controlled vocabularies predominate. For example, the Library of Congress Name Authority File (LC NAF) and Virtual International Authority File (VIAF) controlled vocabulary sources were the most commonly referenced shared vocabularies in the aggregated EAD finding aids for personal names, as shown in the chart depicting the top 10 source values found (figure 1).
| Element | # of elements extracted | % with authfilenumber | % with source |
|---|---|---|---|
| corpname | 504,438 | 5.2% | 46.4% |
| famname | 21,993 | 4.6% | 79.2% |
| genreform | 482,955 | 4.5% | 67.1% |
| geogname | 392,387 | 3.0% | 57.9% |
| persname | 1,092,209 | 8.6% | 54.5% |
| subject | 844,872 | 4.9% | 83.2% |
Thank you to EADdiva for providing the excellent tag library that is linked to from the EAD elements names in this post.
Clustering personal name elements could provide a path to enriching finding aids with controlled vocabulary identifiers
This study also focused on how identity can be established for personal names in EAD finding aids. The persname element describes people who owned or created the materials in collections and others who are noted in or related to the collection materials, as well as archivists and others associated with the stewardship of the collection and creation of the finding aid. It was expected that, in comparison with access terms for organizations, places, subjects, and genres, the people that finding aids refer to may not be as widely represented in shared controlled vocabularies from the library domain, if they are not otherwise associated with published works as creators, contributors, or subjects. The EAD Tag Library provides guidance on the use of the persname element:
All names in a finding aid do not have to be tagged. One option is to tag those names for which access other than basic, undifferentiated keyword retrieval is desired. Use of controlled vocabulary forms is recommended to facilitate access to names within and across finding aid systems.
To what extent has authority control been applied in finding aids to access terms for people?
The personal name investigation began by using the 1,092,209 persname element values that were extracted from the aggregation of NAFAN EAD documents, noted above. The persname element values were then normalized (converted to lower case, extraneous spaces and punctuation removed) and de-duplicated into clusters of matching headings. To produce a more manageable dataset for cleanup and analysis, a cutoff point for the frequency of occurrence of the heading was applied to only include clusters in which the name occurred in 5 or more finding aids. This resulted in a dataset of 20,767 personal name clusters, representing de-duplicated and merged headings from 496,340 persname elements (45% of all the extracted persnames), and including their associated EAD attribute values. This dataset was further modified using the data cleanup tools available in OpenRefine. Those changes included resolving the variant forms of the LC NAF source attribute value (described below) to a single consistent form, converting LC NAF and VIAF identifier numbers in the authfilenumber attribute to a full URL, and de-duplicating LC NAF and VIAF URLs.
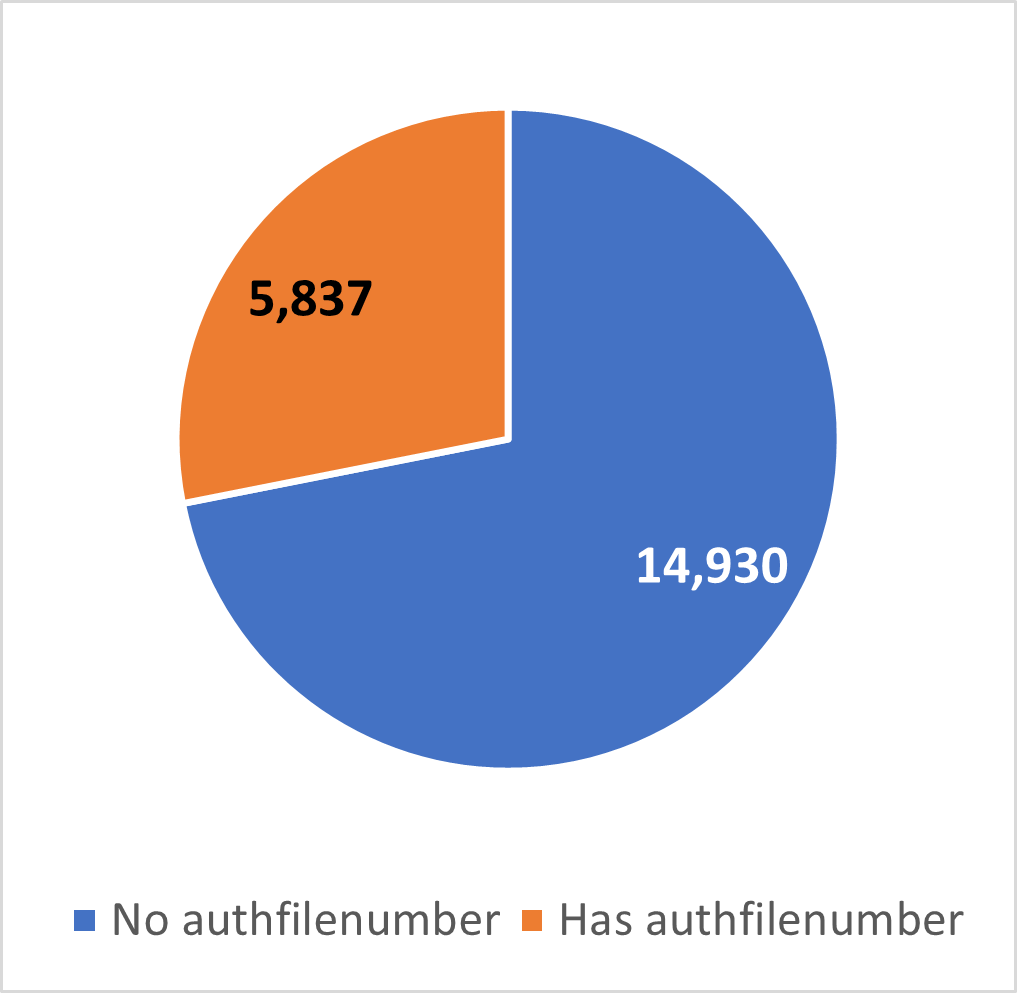
As described in the section below on positive network effects that can be observed in an aggregation, the clustering of personal name elements amplifies the effect of some finding aids having used the source and authfilenumber attributes. While only 8.6% of the total extraction of persname elements included an authfilenumber attribute, in the OpenRefine project based on the 20,767 personal name clusters, 5,837 clusters (28%) included an authfilenumber for the LC NAF, VIAF, or both (figure 2). Since the clusters are based on individual persname elements, some of which may not have had an authfilenumber provided in the source finding aid, the clustering process increased the potential availability of applicable authfilenumber values from 8% to 11%, without any additional reconciliation work.
Automated and manual reconciliation of personal names to a controlled vocabulary can further enrich the clustered elements
A key advantage of working with the OpenRefine tool is that, in addition to providing ways to clean up, transform, and sort data, it can connect to external controlled vocabulary systems and reconcile strings to finding matching authorized headings and their persistent identifiers. This OpenRefine reconciliation feature was used to look for matches in LC NAF for the 11,439 persname cluster names that did not already have an LC NAF or VIAF authfilenumber attribute value in the cluster.
The OpenRefine reconciliation feature can be configured to point to a compatible “endpoint” which uses the OpenRefine Reconciliation API to convert requests into searches sent to the target controlled vocabulary’s system, typically using that system’s API or similar machine-readable data service. For this study, OCLC hosted an instance of a Library of Congress Reconciliation Service for OpenRefine, which is made available under an open source BSD license in the GitHub software repository. Its documentation provides more details on how it interacts with the LC Name Authority file and ranks its results.

The OpenRefine settings for reconciliation include an option for the system to automatically assign a match for any results that are returned from the endpoint with a high confidence. With this setting, the first pass at reconciling the 11,439 persname clusters lacking an authfilenumber automatically matched 3,491 clusters to a LC NAF heading. The percentage of clusters with an authority file number increased after the automated reconciliation and matching, from 28% to 44% (figure 3), and the total number of persname elements that have, or could inherit from the cluster, an authority file identifier increased from 11% to 17%.
The real work of reconciliation is more painstaking and careful, as the personal names that returned one or more potential matches from the LC NAF need to be evaluated, at times consulting their context within the original finding aid, to select or reject suggested matches from the authority file. This work requires diligence, time, and domain expertise. For this study, after clustering similar personal names, finding VIAF and LC NAF identifiers when available from one or more persname elements in the clusters, and looking for automated exact matches using the OpenRefine reconciliation service, there were still over 11,000 persname clusters that would need manual reconciliation and review.

To evaluate the impact of manual reconciliation, the top 500 persname clusters (ranked by the number of finding aids in which the personal name element was found) that lacked either an authfilenumber from the finding aid or an exact match from the first pass of the automated reconciliation process were reviewed. Just 66 of those names were manually reconciled to corresponding LC NAF records, though matches were set only if there was very high confidence in the relationship, without evaluating the name in its finding aid source to obtain more context. The tactic of working with clusters for names that appear many times in many finding aids meant that the 66 manual matches provided identifiers that had an outsized potential impact on finding aids (figure 4), as the total number of persname elements that have, or could inherit from the reconciled cluster, an authority file identifier increased substantially, from 17% to 22%.
Personal name elements in the aggregation represent a long tail and will require substantial resource commitments to establish their identity
This reconciliation study focused on just a subset of the persname element values by working with clusters of names that occurred 5 or more times, ignoring 55% of the extracted values. There is a long tail of infrequently occurring personal names, some of which include too little data to support effective reconciliation (i.e., only providing a surname) and some representing people who are not likely to be found in authority files if they lack a type of literary warrant, not having been a creator of, contributor to, or subject of a published work. They may be accurately tagged as a personal name, but their authority and identity may either be only established locally or not at all. A source attribute value of “local” (or a similar designation) was found in 15.8% of the extracted persname elements.
Variations in source attribute values impede reconciliation
The source attribute is an optional method of identifying the controlled vocabulary source for an element value. When analyzing values in persname elements, 266 unique source attribute values were found, a surprisingly high number given the expected range of controlled vocabularies used for creating archival collection descriptions. But there can be multiple distinct representations of the same vocabulary. For example, the Library of Congress Name Authority File appears to be represented by these distinct source attribute values in the EAD finding aids evaluated for this study:
lc, LC Name Authority File, lca, lcaf, lcanaf, lcanf, lccn, lchs, lcna, lcnaf , lcnaflocal, lcnag, LCNAH, lcnameauthorityfile, lcnat, lcnf, lcnnaf, lcsnaf, library of congress name authority file, library_of_congress_name_authority_file, Library_of_Congress_Name_Authority_File, lnaf, lncaf, lnnaf, naf
Some of these variants may be the result of typographic data entry errors, while others may originate in the finding aid editing interfaces and conversion tools used to create the EAD.
The pareto chart in figure 5 visualizes all the unique source attribute values for the persname elements. As also shown in figure 1, a few attribute values make up the majority of the uses, but (after some additional normalization and clustering of typographically different terms) there are 119 unique source values, some potentially representing the same controlled vocabulary. The infrequently occurring sources likely have important advantages for data management in their “local” context, but in cross-institution aggregation their functional benefits are less clear.

This level of variation can present a barrier to cross-document and cross-aggregation data analysis, as the source attribute value is important for determining what systems to use for reconciliation of headings to persistent identifiers. If a taxonomy of controlled vocabulary source values could be agreed upon and used across finding creation tools, the interoperability of this EAD attribute would improve.
There are potential network effects for name reconciliation in aggregated finding aids
The same person’s name may be found within persname elements in finding aids from multiple repositories. While not all occurrences of that name will have been described with a source or an authfilenumber attribute, in some cases they may be. When many finding aid sources are brought together in a single aggregation, by deduplicating and clustering persname values, there is the potential for enhancing all of the finding aids by inheriting the authfilenumber and source attributes from more completely described names, representing a positive network effect. For example, the personal name string “Obama, Barack” can be found in persname elements in 17 finding aids across the aggregation, but only a few occurrences make use of the authfilenumber attribute. By clustering this data, links to the Library of Congress Name Authority file and VIAF can be derived, and potentially applied to less fully described persname elements in other finding aids, avoiding duplicative or repetitive reconciliation of the access term by each repository.
A positive network effect created by aggregating multiple finding aid sources can also be seen when a personal name cluster is associated with more than one unique identifier from the same controlled vocabulary. For example, in the study of persname values, the cluster for the name “Hamilton, Alexander, 1757-1804” was associated with two LC NAF identifiers. One identifier was correct, the other was not. Discrepancies like these can rise to the surface when multiple sources are aggregated, allowing for detection of the issue and potentially correction.
The aggregation can also help to surface inconsistencies in the controlled vocabulary sources. In this persname study, the cluster for the personal name heading “Parker, Quanah, 1845?-1911” was found to be associated with two different VIAF clusters, which can be reported and likely merged.
Bruce Washburn (retired, 2021) was a Principal Software Engineer in OCLC Research. He provided software development support for OCLC Research initiatives and participated as a contributing team member on selected research projects. He operated the ArchiveGrid discovery system and provided software development support for selected OCLC Products and Services.